혼공머신 (머신러닝+딥러닝) 4주차 미션
기본 미션 : 교차 검증을 그림으로 설명하기
테스트 세트를 사용하지 않고 모델의 과대적합 과소적합 여부를 판단하기 위한 방법이 검증 세트를 만드는 것이다
훈련 세트를 검증 세트로 또 나누는 것이다
주로 20%-30%를 테스트 세트와 검증 세트로 나눈다
훈련 데이터가 많을수록 모델이 좋아지기 때문에 테스트 세트와 검증 세트를 만드느라 훈련 세트가 너무 감소하면 안된다
그렇다고 훈련 데이터를 늘리기 위해 검증 세트를 너무 조금만 나누면 검증 점수가 불안정해진다
교차 검증을 통해 이를 해결할 수 있다
교차 검증은 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복하는 것으로,
안정적인 검증 점수를 얻고 훈련에 더 많은 데이터를 활용하기 위한 방법이다
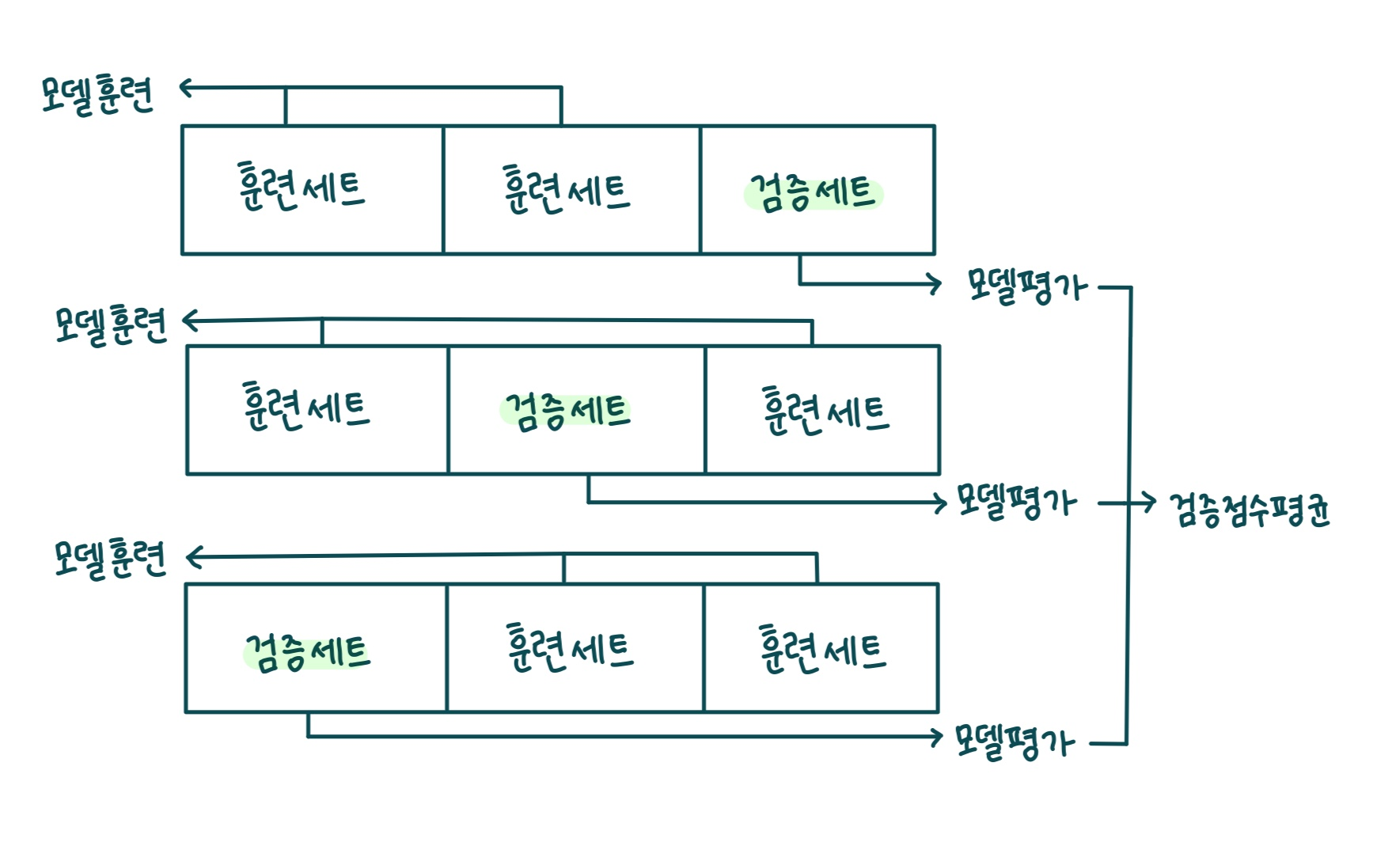
아래 그림은 3-폴드 교차검증을 그림으로 설명한 것이다
3-폴드 교차검증은 훈련 세트를 세 부분으로 나눠서 교차 검증을 수행하는 것이다
통칭 k-폴드 교차검증이라고 한다
선택 미션 : 앙상블 모델 손코딩 화면 캡쳐
앙상블 모델 중 랜덤포레스트 (RandomForestClassifier)와 XGBoost, LightGBM 모델을 손코딩해보았다
안정적 성능을 지닌 모델로, 앙상블 학습 중 널리 사용되는 모델이다
결정 트리를 랜덤하게 만들어 결정 트리의 숲을 만들고, 각 결정 트리의 예측을 사용해 최종 예측을 만드는 학습 방식이다
랜덤 포레스트 모델에서는 각 트리를 훈련하기 위한 데이터를 랜덤하게 만든다
훈련 데이터에서 랜덤하게 샘플을 추출하여 훈련 데이터를 만든다 (중복 가능)
한마디로 복원추출을 하는 것이다
이런 식으로 만들어진 샘플을 부트스트랩 샘플이라고 한다
부트스트랩 샘플은 훈련 세트의 크기와 같다
노드를 분할할 때 전체 특성 중 일부를 무작위로 고른 뒤 그 중 최선의 분할을 찾는다
RF Classifier는 전체 특성 개수의 제곱근만큼의 특성을 선택하고 RF 회귀모델은 전체 특성을 사용한다
기본적으로 RF는 100개의 결정 트리를 이러한 방식으로 훈련한다
랜덤포레스트는 랜덤하게 선택한 샘플과 특성을 사용하기 때문에 훈련 세트에 대한 과대적합을 막아줌과 동시에
검증 세트와 테스트 세트에서의 안정적 성능을 보인다는 장점이 있다 (디폴트 매개변수 값만으로도 결과 굿)

numpy, pandas, train_test_split함수 불러와준다
그리고 wine데이터를 가져와서 wine에 저장해준다
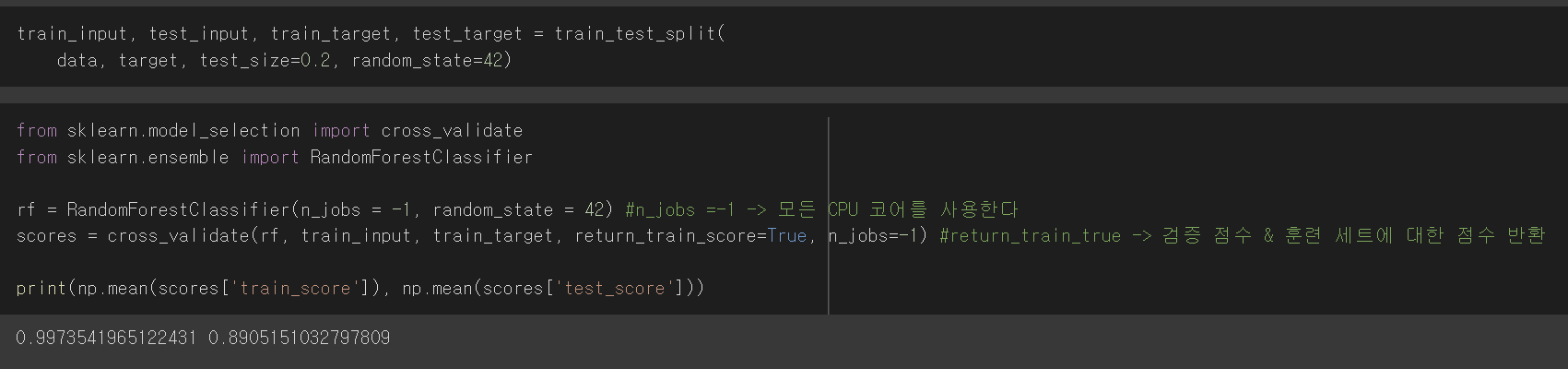
훈련 세트와 테스트 세트를 나눠준다
그리고 교차검증을 위한 cross_validate 함수와 앙상블모델 중 RandomForestClassifier를 임포트해준다
RF Classifier 모델의 n_jobs 매개변수를 -1로 지정하면 컴퓨터의 모든 CPU 코어를 사용한다
cross_validate()의 return_train_score를 True로 지정하면 검증 점수와 훈련 세트에 대한 점수를 모두 반환한다 (디폴트는 False)
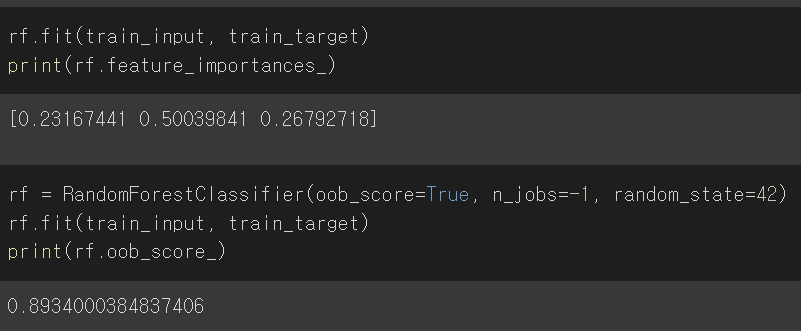
RF Classifier는 결정 트리의 앙상블 모델이기 때문에 각 트리의 특성 중요도를 출력해서 확인할 수 있다
RF Classifier의 특성은 자체적으로 모델을 평가하는 점수를 얻을 수 있다는 점이다
랜덤 포레스트는 훈련 세트에서 중복을 허용하여 부트스트랩 샘플을 만들어 결정 트리를 훈련시킨다
이때 부트스트랩 샘플에 포함되지 않는 샘플을 OOB 샘플이라고 하는데, 이 샘플을 사용해 부트스트랩 샘플로 훈련한 결과를 평가할 수 있다
검증 세트와 유사한 역할을 하는 것이다
oob_score_의 디폴트 값은 False이기 때문에 이 점수를 얻으려면 True로 설정해야 한다
여기서는 0.89로 교차 검증에서의 점수와 비슷한 결과가 나왔다
'study > 혼공학습단 9기' 카테고리의 다른 글
| 혼공학습단 9기 혼공머신 6주차 ! (0) | 2023.02.19 |
|---|---|
| 혼공학습단 9기 혼공머신 5주차 (0) | 2023.02.12 |
| 혼공학습단 9기 혼공머신 3주차 (0) | 2023.01.24 |
| 혼공학습단 9기 혼공머신 2주차 (0) | 2023.01.14 |
| 혼공학습단 9기 혼공머신 1주차 (0) | 2023.01.07 |
